ICAT Schema
Introduction
The schema, which is based on the CSMD, is described below by two diagrams, the first shows the main entities and their relationships. In this note the term entity is often used to denote a set of entities. The second diagram shows those entities which have types or parameters. In the text below all entities are referred to with the same capitalisation they have in the schema.
Main Entities
The first diagram has been simplified by omitting all those entities which have been added to avoid many-to-many relationships. For example an Instrument has many Users and a User may be associated with many Instruments. These are represented by an intermediate entity "InstrumentUser" in this case. Each InstrumentUser relates to one instrument and to one user. These intermediate entities are not shown on the diagram.
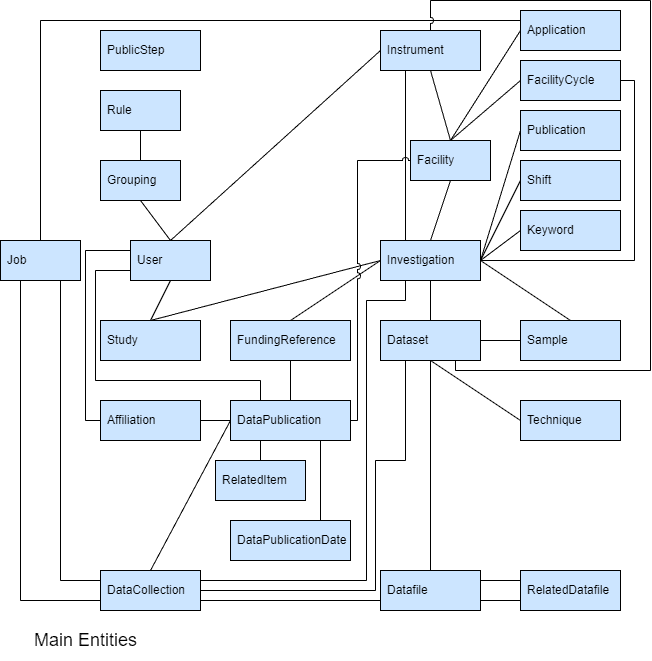
A Facility can be seen as a set of Instruments. Each Facility supports a number of Investigations where there may be a one-to one correspondence between an Investigation and a proposal which is not part of the schema. A Publication corresponds to exactly one Investigation (which is probably bad modelling -- the Publication should be related to a Study representing the output of that study). A facility may also make use of FacilityCycles to define a period of running.
The Investigation has a number of Datasets that belong to it where each Dataset is made up of a number of Datafiles. The Datafile is a physical file with a length and checksum whereas the Dataset is a collection of Datafiles with something in common. In addition there is the notion of DataCollection which groups together individual Datafiles or Datasets of Datafiles which may span Investigations or even Facilities. A DataCollection is used to represent the input to a job and another DataCollection is used for the output. The Job is also related to the Application which converts the input DataCollection to an output.
Samples are associated both with an Investigation to clarify the full set of Samples to be used (partly for safety reasons) and with the Dataset which is related to at most one Sample.
Users are collected together into groups (known here as Groupings to avoid keyword problems) and authorization Rules are associated with these groupings.
Log is used for call logging and PublicStep is to speed up authorization decisions.
Types and Parameters
The second diagram shows those entities (column in the middle of the diagram) with their related parameters in the column to the left of centre and types to the right of centre (where DatafileFormat is here treated as a type.
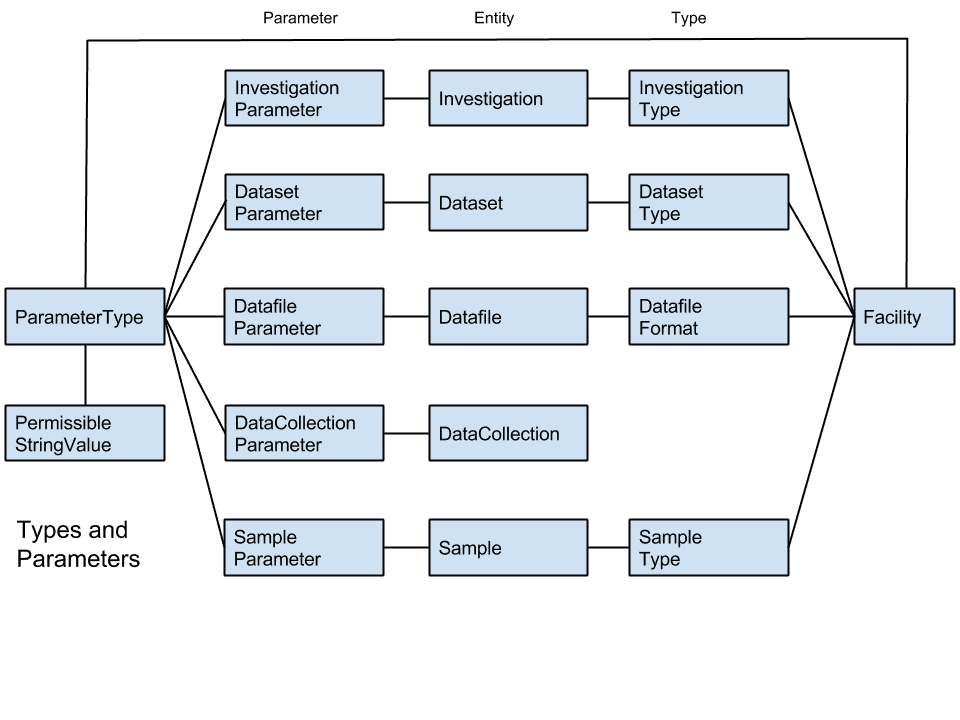
In addition all parameters have a ParameterType and all types are related to a Facility. It is permissible for an entity (such as Investigation) to have a parameter (InvestigationParameter) with a ParameterType belonging to a different Facilty than the Facility to which the Investigation belongs. To achieve some uniformity of naming between facilities a special Facility could be defined to act as a name space with agreed names.
The full schema
The complete schema for each version of ICAT may be seen. For example for 4.10.0. This description of the schema is generated directly from the code. It omits five attributes which are carried by all entitites:
id-- a unique identifier for that entity within the setcreateId-- the username of the creator of the entitycreateTime-- when the entity was createdmodId-- the username of the last modifier of the entitymodTime-- when the entity was last modified
All of these attributes are set by the system but can all be read and used in queries.